
Translation memories have revolutionized the way global businesses and marketing firms localize their content.
You’d be surprised to learn that 82.5% of professional translators use translation memories.
Let’s dive into it, and find out why:
Disclaimer: Localization Academy does not own this content. You can find the original copy here. We are merely sharing this article for the benefit of our localization community. We have received express consent from Redokun to republish this blog post on our platform.
What is Translation Memory (TM)?
A translation memory is a bilingual database containing terms, phrases, sentences, and paragraphs that were previously translated. It essentially consolidates all your existing translation data so you can reuse them in future projects and avoid repetitive work.
Think of a translation memory system as a bilingual dictionary, and you are the curator. The dictionary expands as it recognizes new segments whenever you translate new content.
How does Translation Memory work?
Translation memory encodes language data in pairs. A phrase or a sentence in the source language will have a corresponding translation in the target language. Each pair is called a translation unit.
You can process and transfer your translation memories as a TMX file (short for Translation Memory Exchange, the industry standard) or an Excel file.
When you translate a text using a translation software, your translation memories work in the background by flagging matching or similar segments. Then, they pull up previous translations as suggestions.
These can be 100% matches, where your new content contains segments that are identical to those from a previous project. You can almost always use the past translation word-for-word here.

Suggestions from translation memories can also be fuzzy matches. These are matches that are less than 100% similar. You probably can’t reuse the past translation from your database word-for-word. However, you can retrieve and modify it to suit the new content.
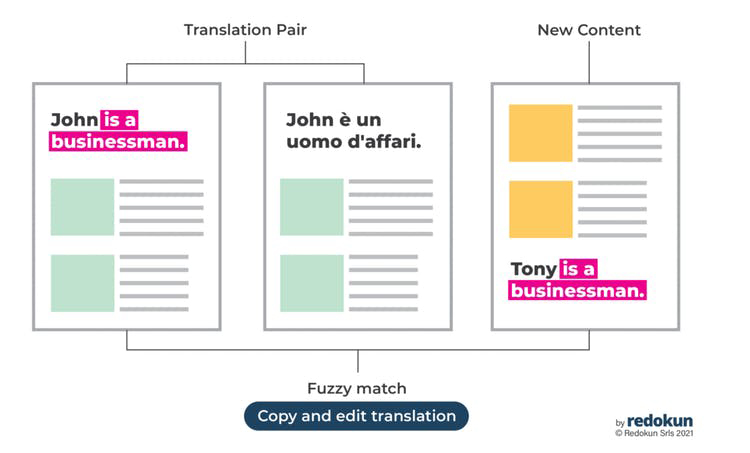
Of course, translation memory and fuzzy matches can be much more sophisticated than the examples we’ve given here. The translation software you use may also analyze the context, punctuations, word order, and spelling variations while searching for matches in your translation memories.
Here is a detailed guide about everything translation software can do for you.
Benefits of Translation Memory
To contextualize the use of translation memories in localization, let’s say you need to translate a furniture catalog.
Every year, the catalog is updated to include new pricing, new products, and revised product descriptions. This means that with every new update, you will have a combination of text segments that are:
- the same as last year’s catalog
- slightly different from last year’s catalog
- completely new
Should you translate from scratch? Or should you go through the catalog manually for similarities and differences? The most productive method is to use translation memories, and here’s why.
1. Work Faster, Save Time
The translation memory software automatically highlights identical matches and mark up fuzzy matches for further action.
This saves you from having to play a game of “spot the difference” yourself, giving you more time to focus on new segments you have not translated before.
2. Create Consistent Content
A translation memory ensures you never translate the same thing twice. This could be a catchphrase your company likes to use in all communications, or complex translations that can serve as a reference for future projects.
3. Be Cost-Effective
By building a database of translation memories, you won’t necessarily need to hire a professional translator for subsequent localization projects. You can pre-translate a text using your translation memories, then ask a colleague to proofread and edit.
It’s free to reuse past translations! What more can I say?
4. Centralize Your Data
Perhaps you need to refer to a past project under a different department? Keep all your company’s translation data in one place with a translation memory software. Now anyone on your team can easily look up relevant segments while localizing new content.

Where can I use Translation Memory?
A translation memory on its own is not a software you can use to translate files.
Since it is a database, you need to upload and use them within a computer-assisted translation software like Redokun.
Below is an example from Redokun’s web editor, which organizes the original text and its translation side-by-side for easy viewing.
A translation memory appears under the translation text box, indicating that there is an 87% fuzzy match from a previous project.
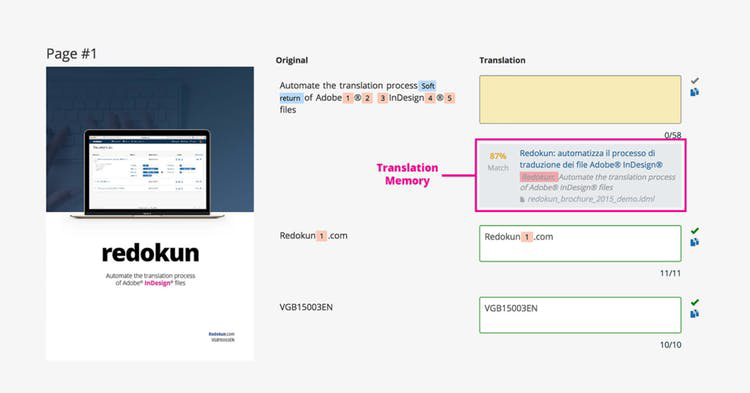
What you would do here is to copy the old translation and tweak it so that it corresponds to the new content.
To be more efficient, you can also pre-translate a document based on identical segments between your translation memories and the new content. There are two optional levels of pre-translation here: 100% Match with same context and 100% Match.
Same context simply means that the matching segments in the old and new content also share the same surrounding text. Here’s how pre-translation looks in Redokun’s web editor:

The pre-translate feature will automatically insert all the 100% matching segments into the translation text boxes, so you don’t need to do it manually (even more importantly – this can be done when translating various file formats such as InDesign and Office documents such as Word documents, Excel spreadsheets, PowerPoint presentations).
Common Misconceptions about Translation Memories
Misconception #1: Translation memories are unreliable because they are a kind of machine translation.
While translation memory offers automatization, it should not be mistaken for machine translation. Translation memories are built from the efforts of real people who translated and approved past projects.
In other words, you are collecting and consolidating the work you might have commissioned a translator or someone else in your company to do.
The resulting database is like a gold mine where you can dig up previous translations and reuse them for free.
Misconception #2: Translation memories are not useful to my business because our texts are not repetitive.
Whether you deal with repetitive texts or not, fuzzy matches can still be useful. This is especially true for language pairs with similar word order (e.g. English-Malay).
In these cases, leveraging fuzzy matches could be a faster way to translate. Segments that are similar in terms of sentence structure can serve as building blocks for the translator or proofreader.
Furthermore, the more you build your translation memories, the richer the content. There is bound to be some repetition in terms of syntax, which you can reference while translating new content.
Summary
Translation memories are your biggest assets for localization. They speed up your multilingual workflow and ensure consistency across all your localization projects.
Furthermore, building a translation memory reduces your need to hire a professional translator every time there is new content to localize.
It’s basically “reduce, reuse, recycle”… but for translations.
Hope this article helped you,
Shu Ni


